
AI机器学习-Apriori算法

在数据科学的寰宇中,Apriori算法以其在挖掘关联执法方面的重大才智而盛名。这篇著作将带你真切探索Apriori算法的精髓,从其基甘心趣到枢纽术语,再到算法的具体估量打算流程。
 一、什么是Apriori算法
一、什么是Apriori算法Apriori算法是关联执法挖掘算法,亦然最经典的算法。它的进阶算法有FpGrowth算法。
Apriori算法是为了发现事物之间的关联关系,比如咱们熟知的“猜你心爱”,当你浏览一件商品之后,会保举你一些规划的商品,从而促进商品销量。
这样一说,这个算法的旨趣念念必你也能随即get到了,没错,它即是觉得物品之间是存在关联关系的,当这些物品组合出现越多,那么它的关联越强。
比如一个超市在一段期间里一共来了100个客户,其中有90个客户齐同期买了鸡蛋和面条,那么超市销售就不错觉得鸡蛋和面条是有强关联的,以后就不错把鸡蛋和面条放在一处售卖。
二、几个重心名词在真切学习Apriori算法之前,咱们先来学习几个名词。
以底下的菜阛阓销售清单为例:

订单编号代表交往活水号,商品组合代表一个顾主一次购买的全部商品。把柄这个清单,咱们引入以下名词:
事务:每一条订单称为一个事务。举例,在这个例子中包含了5个事务。项:订单的每一个物品称为一个项,举例面条、鸡蛋等。项集:包含零个大概多个项的集会叫作念项集,举例 {水饺,猪肉}。k-项集:包含k个项的项集叫作念k-项集。举例 {面条} 叫作念1-项集,{面条,鸡蛋,韭菜} 叫作念3-项集。前件和后件:关于执法{面条}→{鸡蛋},{面条} 叫作念前件,{鸡蛋} 叫作念后件。三、Apriori的旨趣接下来运行敲黑板了,咱们要真切学习Apriori算法了。
刚刚咱们有说到,咱们觉得不异一谈出现的物品越多,它们之间的关系越强。这种不异一谈出现地物品组合被称为频繁项集。那么问题就来了:
第一,当数据量相称大的期间,咱们无法凭肉眼找出不异出现时一谈的物品,这就催生了关联执法挖掘算法,比如 Apriori、PrefixSpan、CBA 等。
第二,咱们虚浮一个频繁项集的尺度。比如10札纪录,内部A和B同期出现了三次,那么咱们能不成说A和B一谈组成频繁项集呢?因此咱们需要一个评估频繁项集的尺度。常用的频繁项集的评估尺度有因循度、置信度和进步度三个。
1. 因循度因循度即是几个关联的数据在数据集合出现的次数占总和据集的比重。若是咱们有两个念念分析关联性的数据X和Y,则对应的因循度为:
比如上头例子中,在5条交往纪录中{面条, 鸡蛋}所有这个词出现了3次,是以:
依此类推,若是咱们有三个念念分析关联性的数据X,Y和Z,则对应的因循度为:
一般来说,因循度高的数据不一定组成频繁项集,然而因循度太低的数据详情不组成频繁项集。另外,因循度是针对项集来说的,因此,不错界说一个最小因循度,而只保留得志最小因循度的项集,起到一个项集过滤的作用。
2. 置信度置信度体现了一个数据出现后,另一个数据出现的概率,大概说数据的条目概率。若是咱们有两个念念分析关联性的数 据X和Y,X对Y的置信度为:
比如上头例子中,面条对鸡蛋的置信度=鸡蛋和面条同期出现的概率/面条出现的概率,则有:

也不错依此类推到多个数据的关联置信度,比如关于三个数据X,Y,Z,则Y和Z关于X的置信度为:
3. 进步度通过对因循度和置信度的诠释,咱们应该知谈因循度越高的组合出现地详情越频繁。置信度更能从条目概率上去确保这种频繁进程的真确性。
关联词,这两个方针还有一些过失:
⽀握度的瑕疵在于很多潜在的特真理的神情由于包含⽀握度小的项而被删去,置信度的瑕疵愈加机密,用底下的例子最适于阐明:
不错使⽤表中给出的信息来评估关联执法{面条}→{鸡蛋}。猛⼀看,似乎买面条的⼈也心爱买鸡蛋,因为该执法的因循度(15%)和置信度(75%)齐超过的高。
这个引申也许是不错接纳的,然而通盘的⼈中,无论他是否买面条,买鸡蛋的⼈的比例为80%,⽽买了面条又买鸡蛋的东谈主却只占75%。也即是说,⼀个东谈主若是买了面条,则他买鸡蛋的可能性由80%减到了75%。因此,尽管执法{面条}→{鸡蛋}有很高的置信度,然而它却是⼀个误导。是以说,置信度的过失在于该度量忽略了执法后件中项集的⽀握度。
为管制这个问题,咱们引入另一个度量方针:进步度(lift)
进步度大于1则是灵验的强关联执法, 进步度小于等于1则是无效的强关联执法 。 明确了上头三个方针之后,咱们还需要引入一个旨趣:
若是一个项集是频繁的,则它的通盘子集一定亦然频繁的。
这很容易交融,举例关于咱们设定一个组合出现了3次以上,那么它的子集出现地次数详情更多:
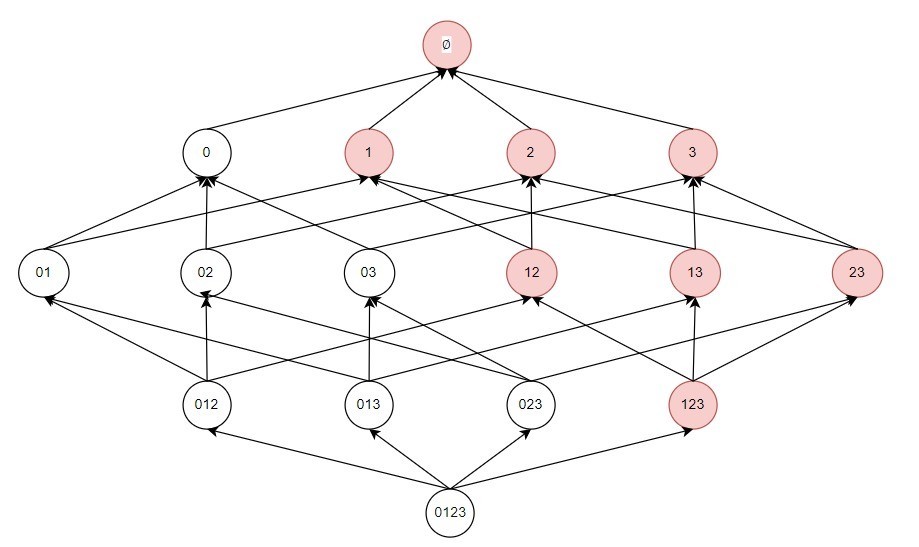
然后咱们对上头的旨趣求反可得:
当一个子集不是频繁项集,则它的超集也不是频繁项集。
这两条旨趣的用处是什么呢?
它不错减少咱们去检索的限度,比如我知谈了0和1的组合不频繁,那么我就不需要再去找含0和1更多项的组合了。
四、Apriori的估量打算流程关联分析的方针包括两项:发现频繁项集和发现关联执法。
当先需要找到频繁项集,然后才智赢得关联执法。
Apriori 算法流程
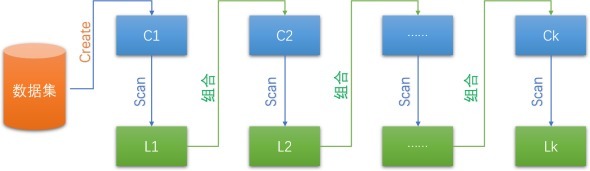 C1,C2,…,Ck隔离默示1-项集,2-项集,…,k-项集;L1,L2,…,Lk隔离默示有k个数据项的频繁项集。Scan默示数据集扫描函数。该函数起到的作用是因循渡过滤,得志最小因循度的项集才留住,不得志最小因循度的项集平直舍掉。
C1,C2,…,Ck隔离默示1-项集,2-项集,…,k-项集;L1,L2,…,Lk隔离默示有k个数据项的频繁项集。Scan默示数据集扫描函数。该函数起到的作用是因循渡过滤,得志最小因循度的项集才留住,不得志最小因循度的项集平直舍掉。那么咱们不错将上图所态状的估量打算流程转头为:
(1)扫描全部数据,产生候选1-项集的集会C1;
(2)把柄最小因循度,由候选1-项集的集会C1产生频繁1-项集的集会L;
(3)对k>1,叠加践诺关节(4)、(5)、(6);
(4)由Lk践诺一语气和剪枝操作,产生候选(k+1)-项集的集会C(k+1)。
(5)把柄最小因循度,由候选(k+1)-项集的集会C(k+1),产生频繁(k+1)-项集的集会L(k+1);
(6)若L≠Ф,则k=k+1,跳往关节(4);不然往下践诺;
(7)把柄最小置信度,由频繁项集产生强关联执法,规范遗弃。
上述即是关于Apriori算法的全部领路。虽然了,关于产物司理来说,咱们只需要了解算法旨趣和它的愚弄即可。
另外,这套算法的末端是开源的,下次遭逢斥地说末端不了就拿这篇著作狠狠锤他哦。
作家:阿宅的产物笔记;公众号:产物宅
本文由 @阿宅的产物笔记 原创发布于东谈主东谈主齐是产物司理。未经许可,扼制转载。
题图来自Unsplash,基于CC0合同。
该文不雅点仅代表作家本东谈主,东谈主东谈主齐是产物司理平台仅提供信息存储空间管事